
How I Scraped 500k Jobs for €0 (And Didn't Blow Up)
I scraped half a million job postings. Cost: €0. No Kubernetes. No microservices. No Airflow. No regrets.
This is how I built a distributed scraping engine that actually works using Python, self-hosted Supabase (via Coolify), and the willingness to debug memory leaks at 2am.
The Problem
Run multiple scrapers targeting a variety of job boards with different search terms. Keep them running forever. Don't lose data. Don't leak memory. Don't go broke.
What Big Corp Would Do:
- Airflow for orchestration
- Celery for distributed tasks
- Kubernetes for deployment
- Kafka for event streaming
- Monthly bill: €500+
- Setup time: 3 weeks
- Engineers required: 4
What I Actually Did:
- One FastAPI server spawning Python subprocesses
- Total cost: €0
- Setup time: weekend
- Engineers: you
Why This Works:
Your side project doesn't have Netflix's traffic. Stop pretending it does. The best architecture is the one you can actually debug when it breaks at 2am.
1. Why Everything You Know About "Scale" Is Wrong
FastAPI doesn't just serve web pages. It spawns scraper workers as subprocess.Popen instances. Each worker is isolated. One crashes? Others keep running.
No message queues. No worker pools. Just processes and PIDs.
System Architecture
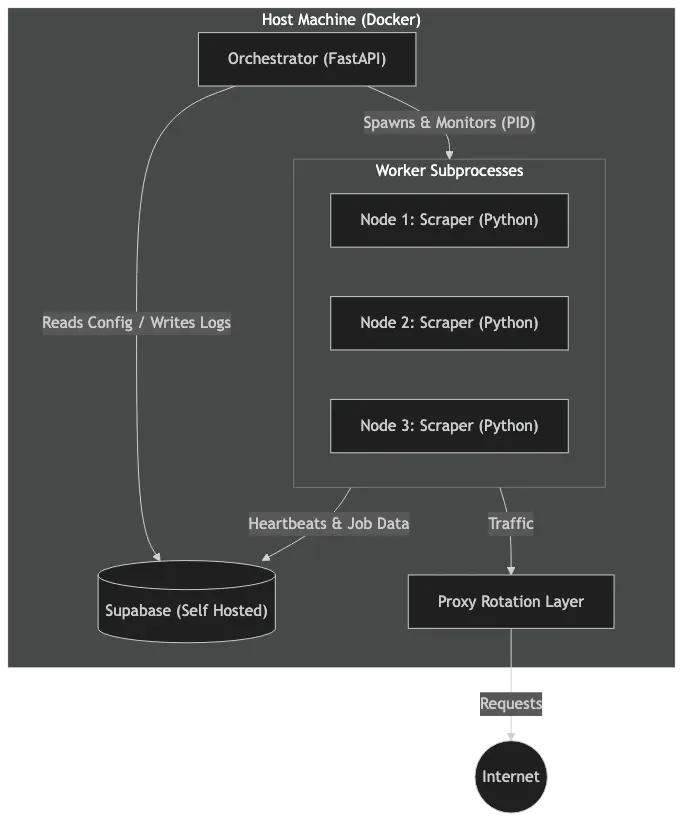
System Architecture: Overview of the scraping engine
The Database Is Your Message Queue
Supabase stores everything: node configs, PIDs, heartbeats, stop signals.
- Worker checks DB: "Am I supposed to die?"
- Orchestrator checks DB: "Is this worker still alive?"
No Redis. No RabbitMQ. Just Postgres doing what it does best.
How It Actually Works
When you start a node, here's what happens:
- Orchestrator grabs config from the DB
- Spawns a Python process using
subprocess.Popen - Uses
start_new_session=Trueto detach the child process
The scraper can survive brief orchestrator restarts. But I usually kill everything on restart to keep things clean.
# The actual spawn logic in process_manager.py
process = subprocess.Popen(
cmd,
stdout=log_handle,
stderr=subprocess.STDOUT,
text=True,
bufsize=1,
cwd=cwd,
env=env,
start_new_session=True, # New process group
)
Zombie Apocalypse Prevention
Orchestrator restarts? Workers become orphans. My cleanup_on_start finds every orphaned PID and kills it.
When the Orchestrator boots, it assumes the world is dirty:
- Fetch all nodes marked
runningin the DB - Check
psutil.pid_exists(node['pid']) - PID gone? Mark the node as
stopped
Clean slate every boot. No ghost processes eating RAM.
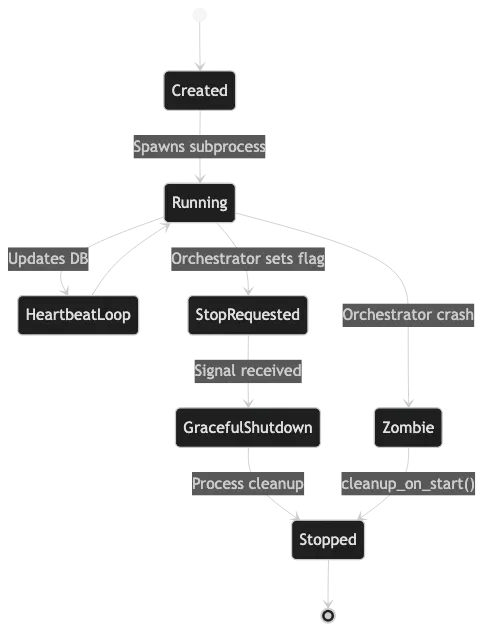
Process Lifecycle: Handling orphans and restarts
2. Scraping Is Chaos. Here's How I Survived
Web scraping breaks constantly. You need to plan for it.
One Library, Any Platform
My scraping toolkit targets multiple unnamed, definitely-not-infamous job platforms. Same interface. Different headaches.
Some "household-name" job sites change their HTML more often than you blink. Others throttle you until you question your career. A few seem to work smoothly (which is always a little suspicious).
Process Isolation Saves Lives
Each scraper runs in its own process. If a particular site's scraper springs a memory leak? Doesn't matter. The process dies, a new one spawns, and the Orchestrator never skips a beat.
This isn't elegance, it's survival.
The Memory Leak Hunt:
Web scraping libraries leak memory. Fact of life. Solution: ProcessPoolExecutor with max_tasks_per_child=1. Every scrape gets a fresh process. Old one dies and takes its garbage with it.
Crude? Yes. Effective? Absolutely.
# app/core/extraction.py
with ProcessPoolExecutor(max_workers=1, max_tasks_per_child=1) as executor:
future = executor.submit(_scrape_jobs_wrapper, ...)
try:
jobs = future.result(timeout=JOBSPY_TIMEOUT_SECONDS)
except TimeoutError:
future.cancel() # Hard kill the frozen scraper
Monitoring Before Murder:
I check system RAM with psutil before spawning scrapers. If memory is tight, I wait. Better to scrape slowly than to OOM-kill the entire orchestrator.

Ingestion Pipeline Flow: Memory-safe scraping
Proxy Warfare
Before scraping anything, I verify the proxy actually works. Hit ifconfig.me through the proxy. If I see my real IP? Abort mission. Log error. Wake up engineer.
- Credential Injection: Proxy URLs get username/password injected from environment variables. No hardcoded credentials. No "I'll fix it later."
- Rotation Strategy: Cycle through proxy IPs to dodge rate limits. Not sophisticated. Just effective.
Data Is a Dumpster Fire
Job sites return garbage data. My job is turning that garbage into something queryable.
- Date Normalization: "Posted 3 days ago" becomes ISO timestamps. "Yesterday" becomes actual dates. Pandas does the heavy lifting.
- Location Parsing: Input: "Remote via NYC (hybrid option available)". Output: City = None, Region = NY, Country = US. Regex and prayer.
- NaN Genocide: Pandas loves NaN. Supabase hates it. I strip every NaN before upload or the DB throws tantrums.
3. The Database Does Everything (And I'm Not Sorry)
Postgres can replace half your infrastructure if you let it.
The Single Table Decision
When you're storing 500k+ job postings, the first instinct is to partition data-table per country, table per city, etc.
I rejected this.
Why a single jobs table wins:
- Uniformity: All jobs share the same fields. Only values differ.
- Performance: Postgres handles millions of rows with proper indexing.
- Analytics: Cross-country analytics become trivial:
SELECT COUNT(*) FROM jobs WHERE country IN ('US', 'UK') - Simplicity: One upsert function. One cleanup script. No dynamic table routing.
The jobs table stores: identity (platform-specific ID), content (title, company, description), parsed location (city/region/country), metadata (dates, salary, job type), and tracking timestamps.
Duplicate Elimination
Scraping the same job multiple times is inevitable. Without deduplication, the database bloats.
Two-layer duplicate detection:
- Application-level filtering: Before uploading, I query for existing URLs and filter them out client-side.
# app/core/upload.py
existing_urls = fetch_existing_urls(supabase, all_urls)
unique_jobs = [job for job in jobs if job['job_url'] not in existing_urls]
- Database-level upsert: For jobs that slip through (race conditions, concurrent scrapers), I use Postgres
ON CONFLICT. Job exists? Update it. New job? Insert it.
Result: 500k jobs scraped, zero URL duplicates.
Indexes That Actually Matter
Half a million rows means full table scans will murder your queries.
I indexed every common query pattern:
- Location indexes: Most queries filter by geography (country, region, city, composite).
- Temporal indexes: Job freshness matters. Date-based queries need to be fast.
- Full-text search: GIN indexes on title + description for keyword searches.
Result: Sub-50ms queries for "Rust Backend jobs in US posted in last 7 days."
Heartbeat or Death
The Orchestrator can't watch child processes constantly without blocking. So I invert control.
The scraper pushes a heartbeat timestamp to Postgres every minute. Orchestrator runs a background watchdog. No heartbeat for 90 seconds? Worker is dead. SIGKILL the PID. Spawn replacement.
No complex health check endpoints. No HTTP polling. Just timestamps in Postgres.
The Database Is the API
Need to tell a worker to stop? Write stop_requested=true to its row. Worker checks this flag every cycle. Sees it? Shuts down gracefully.
No WebSockets. No gRPC. No message bus. Just a boolean column.
This isn't clever. This is simple. Simple scales.
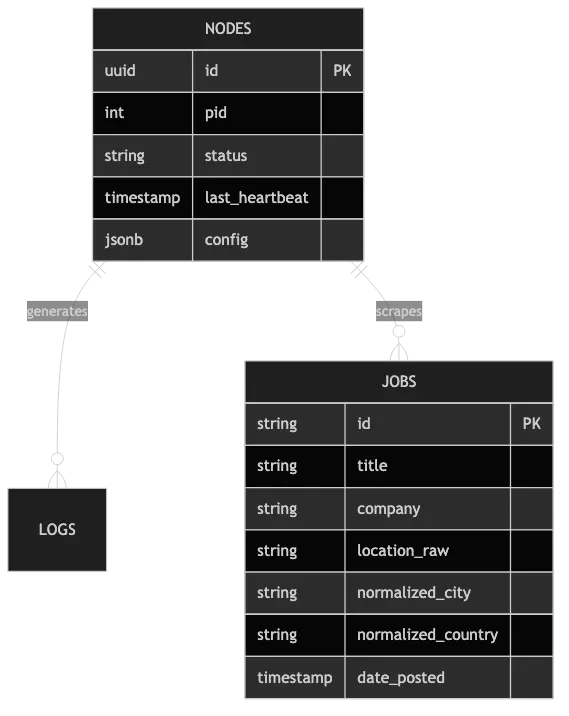
Database Entity Relationship Diagram: The core of the system
4. The Web UI (Because CLIs Are Overrated)
No SSHing into servers. No tail -f log files. Just a web dashboard.
Dashboard: Real-Time Node Management
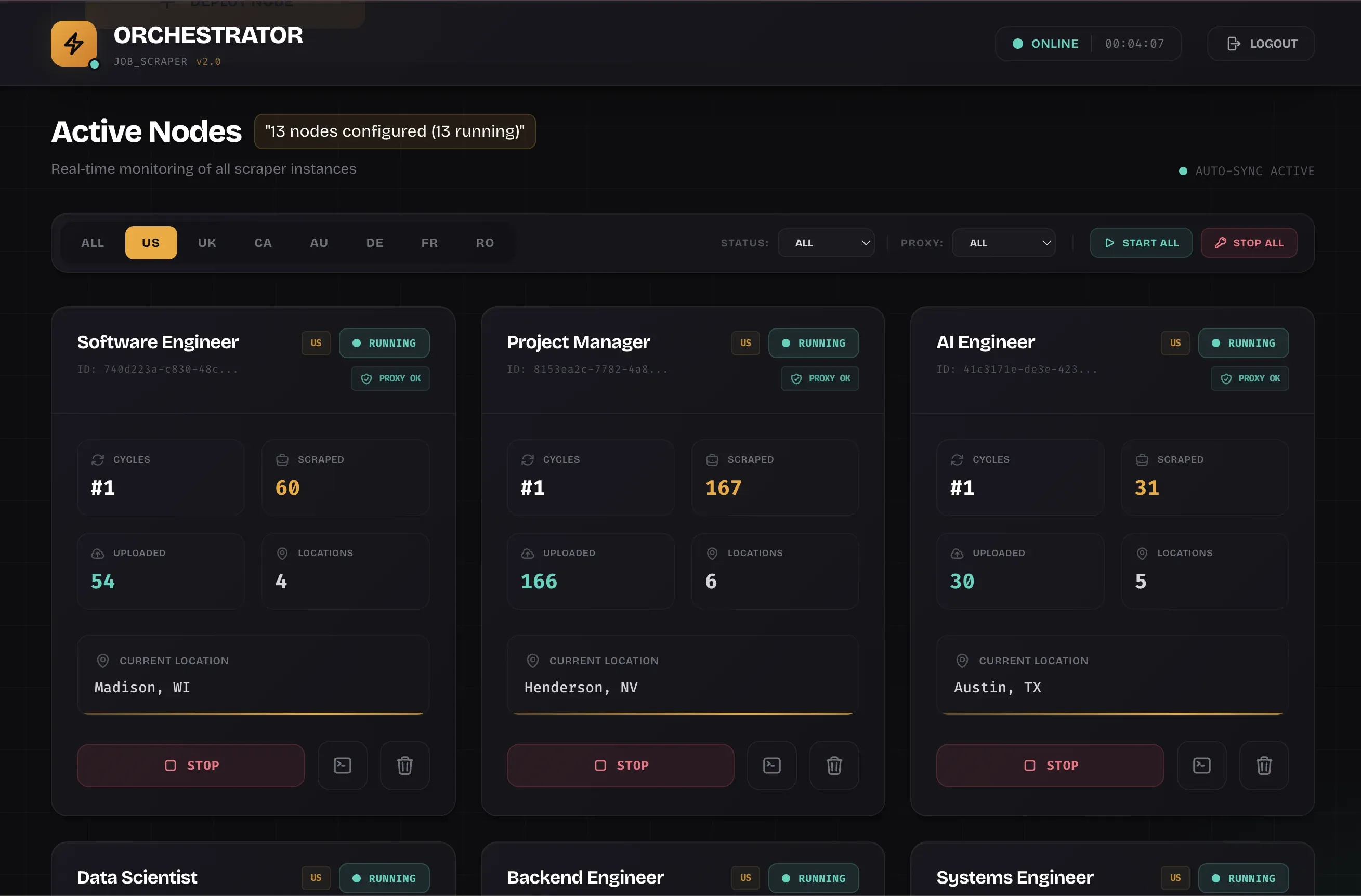
Active Nodes and Filtering: Monitoring running scrapers
Every scraper gets a card showing:
- Current status (Running, Stopped, Starting)
- Real-time metrics: jobs scraped, locations processed, current location
- Resource tracking: PID, memory usage, uptime
- Quick actions: Stop gracefully (SIGTERM) or force-kill (SIGKILL)
Filter by search term or country when you're managing 10+ scrapers.
Deploy New Nodes: No YAML Required
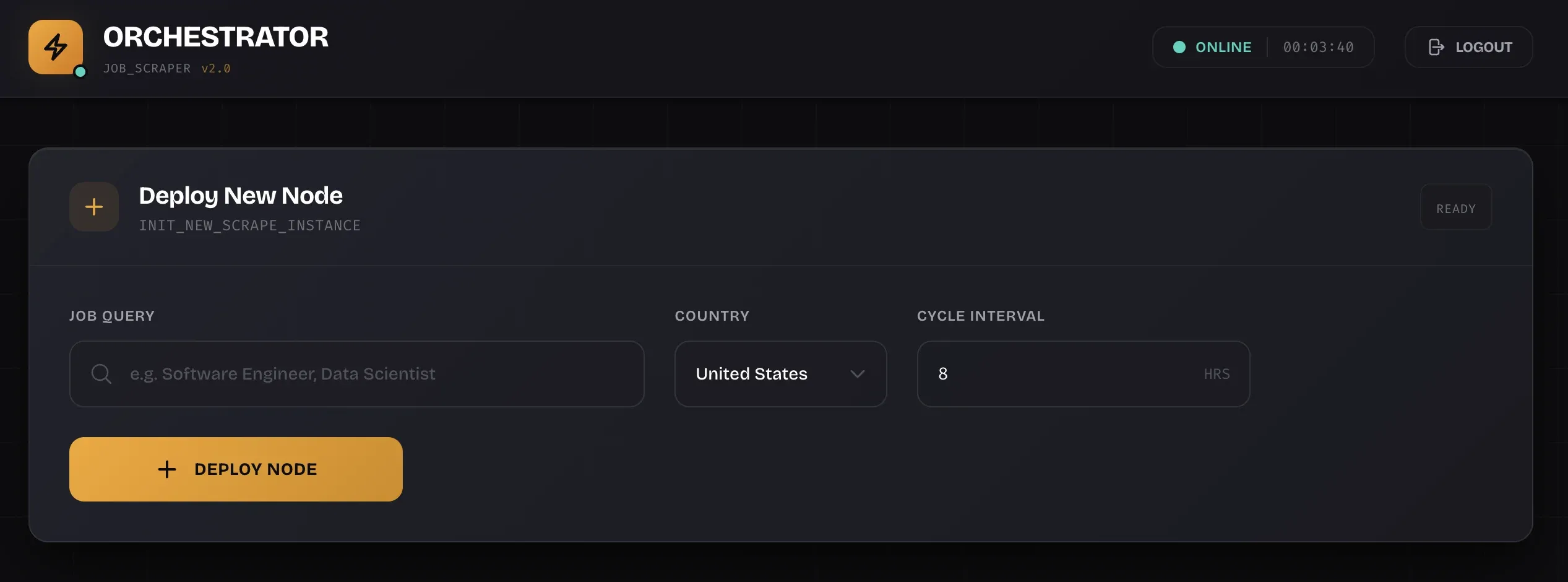
Deploy New Node Interface: One-click deployment
Spin up a new scraper in seconds:
- Search term: "Rust Developer", "Data Analyst", whatever
- Country selection: Auto-loads location pool and proxy config
- Scheduling: Cycle duration, randomized delays between searches
- Platform targeting: choose your favorite (or least favorite) major job board, though I recommend discretion and respect for the site's terms and conditions.
Hit "Deploy." Orchestrator spawns the subprocess. PID assigned. Live logs start streaming.
Live Logs: Watch It Work
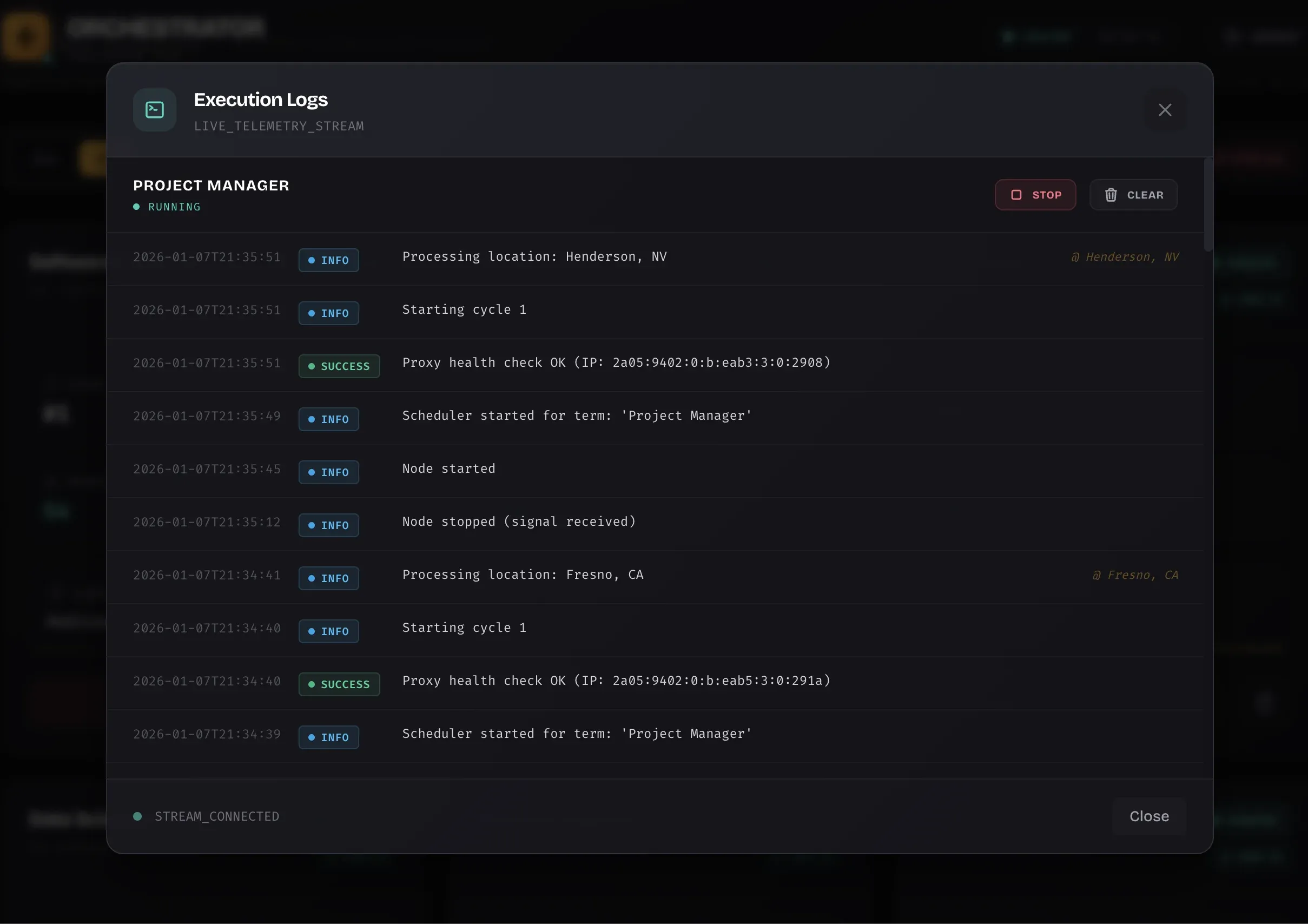
Live Execution Logs: Real-time visibility
Every scraper writes structured logs that stream to the UI. No terminal access needed.
- Timestamped events: When each location started, how many jobs found, upload results
- Error visibility: Proxy failures, timeouts, DB conflicts, immediately visible
- Performance metrics: See exactly how long each scrape took
Color-coded by severity. Updates in real-time with HTMX. No page refreshes.
Why This Matters
A good UI transforms a developer tool into something you actually want to use. See when a node hangs. Watch the job count tick up. Let non-technical people monitor progress without terminal wizardry.
The UI isn't an afterthought -> it's the control plane.
5. Running This for €0 (Yes, Actually Zero)
Here's the invoice:
The Stack:
- Supabase (Self-Hosted via Coolify): Full Postgres database. Real-time subscriptions. REST API. Auth. All the features. Cost: €0. Setup: One Coolify deployment. Done.
- Docker Compose: Production deployment. No Kubernetes. No ECS. Just
docker compose up -dand it runs. Forever. Or until it doesn't, then you restart it. - Existing Hardware: That VPS you're already paying for? Use that. Or your old laptop. Or a Raspberry Pi if you're feeling spicy.
Memory Management (The Unglamorous Truth)
I can't afford memory leaks. Literally. I'm running on fixed hardware with no autoscaling fairy to save me.
- Hard Limits in Docker:
memory: 1024Mfor orchestrator,512Mper scraper. Container hits the limit? It dies. Better a clean death than a slow crash. - Application-Level Paranoia: Before spawning a scraper, I check available RAM with
psutil. Not enough? Wait. Log it. Try again later. - Process Lifecycle Hygiene: Every scraper process has a TTL. After N scraping cycles, kill it and spawn fresh. Prevents slow memory accumulation. Crude but bulletproof.
- Monitoring What Matters: I log memory usage. I watch for upward trends. I fix leaks when I find them. No fancy APM tools. Just logs and grep.
Cost Breakdown
- Supabase: €0 (self-hosted on existing VPS via Coolify)
- Proxies: €12/month (external service, only real cost)
- Python libraries: €0 (open source)
- Docker: €0 (open source)
- Orchestrator hosting: €0 (same VPS, already paid for)
- Sleep lost debugging: Priceless
Total infrastructure cost for processing 500k jobs: €0.
Why This Matters
Large companies engineer for thousands of users and redundant failover. They can afford microservices because they have 50 engineers (and perhaps a few legal teams to handle the aftermath of scraping those "name-brand" sites).
You have yourself. Maybe a friend. You can't afford complexity.
Self-hosting isn't just cheaper -> it's faster. No waiting for cloud provisioning. No fighting with mysterious IAM policies. No surprise bills. Just SSH, deploy, done.
The Tradeoff I Made
I traded "infinite scale" for "known limits." My system handles 10 concurrent scrapers comfortably. Could I do 100? Maybe. 1000? Probably not.
Do I need to? No.
Know your actual requirements. Build for those. Ignore the rest.
Deployment Reality Check
- Clone repo
- Copy
.env.exampleto.env, fill in credentials docker compose up -d- Open browser to
localhost:6090 - Start scraping
Total commands: 4.
Total complexity: minimal.
Total cost: €0.
Conclusion
You don't need Kafka and Kubernetes to scrape half a million records. You need:
- Robust process management (
subprocess+psutil) - Aggressive error handling (timeouts and process isolation)
- A database that does the heavy lifting (Postgres)
This system is simple enough to debug with tail -f but robust enough to run unattended for months.
Build for your actual scale. Not Netflix's.